Apache Parquet : Le format de stockage incontournable pour le Big Data
Apache Parquet est le format de stockage colonnaire incontournable pour le Big Data. Optimisé pour la performance et la compression, il accélère les requêtes et réduit les coûts. Intégré à Spark, Iceberg et les architectures lakehouse, Parquet offre interopérabilité et efficacité.


Introduction
Dans l'écosystème moderne du big data, le choix du format de stockage est crucial pour garantir performance, efficacité et interopérabilité. Apache Parquet s'est imposé comme un standard incontournable, notamment pour les architectures data lake et lakehouse. Dans cet article, nous explorons le rôle central de Parquet, ses avantages, et comment il s'intègre avec des outils comme Apache Spark, Apache Iceberg, et bien d'autres.
Qu'est-ce qu'Apache Parquet ?
Apache Parquet est un format de fichier colonnaire open-source, optimisé pour le stockage et le traitement de volumes massifs de données. Contrairement aux formats orientés ligne (comme CSV ou JSON), Parquet organise les données par colonnes, ce qui offre plusieurs avantages clés :
- Performance : Réduction des I/O en ne lisant que les colonnes nécessaires.
- Compression efficace :
- Parquet utilise des algorithmes de compression (comme Snappy, GZIP ou LZO) pour réduire la taille des fichiers.
- Les données d'une même colonne ont souvent des valeurs similaires ou répétées, ce qui permet une compression optimisée (via des techniques comme le dictionary encoding ou le bit packing).
- Par défaut, Spark utilise Snappy (équilibre entre vitesse et compression), tandis que GZIP offre un taux de compression plus élevé au prix d'une légère latence.
- Compatibilité : Supporté par la plupart des outils Big Data (Spark, Hive, Presto, etc.).
Parquet est devenu le fondement de nombreuses solutions modernes, des data lakes aux architectures lakehouse.
Parquet dans l'écosystème Big Data
1. Parquet et Apache Spark
Apache Spark, le moteur de traitement distribué, utilise Parquet comme format par défaut pour ses opérations de lecture/écriture. Cette intégration native permet :
- Des requêtes plus rapides grâce à des optimisations telles que le column pruning (élimination des colonnes non pertinentes pour la requête) et le predicate pushdown. Ce dernier permet à Spark de "pousser" les conditions de filtrage (par exemple, les clauses
WHEREd'une requête SQL) directement au niveau de la lecture des fichiers Parquet. Ainsi, seules les données répondant aux critères sont chargées en mémoire, réduisant considérablement le volume de données à traiter. - Une interopérabilité avec d'autres outils comme Hive ou Presto.
- Un stockage économique grâce à la compression.
Exemple d'utilisation avec Spark :
# DataFrames can be saved as Parquet files, maintaining the schema information.
df.write.parquet("path/to/file.parquet")
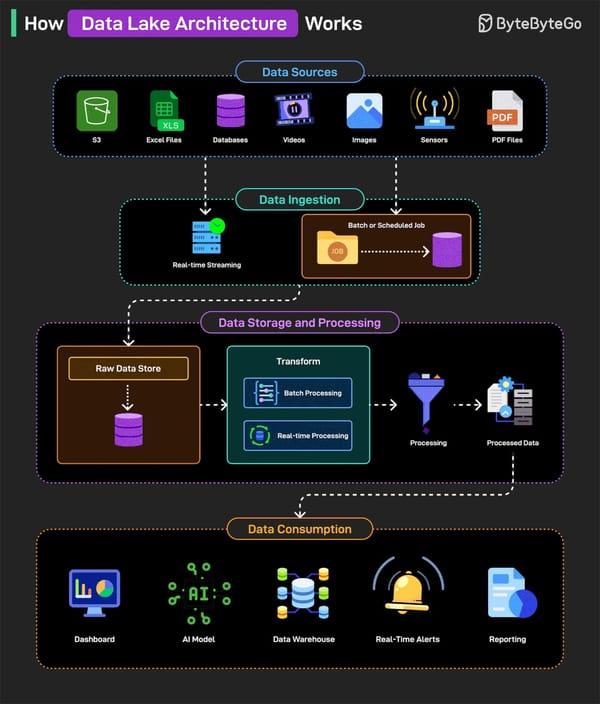
2. Parquet et les data lakes
Dans un data lake, Parquet est souvent associé à des métadonnées (comme Hive Metastore) pour permettre des requêtes SQL efficaces. Cependant, les data lakes traditionnels manquent de fonctionnalités avancées comme les transactions ACID, d'où l'émergence des lakehouses.
3. Parquet et les lakehouses
Les solutions lakehouse (comme Delta Lake, Apache Hudi, et Apache Iceberg) utilisent Parquet comme format de stockage sous-jacent, mais y ajoutent des couches de métadonnées pour :
- Les transactions ACID.
- Le Time Travel (accès aux versions précédentes des données).
- La gestion des schémas.
Par exemple, Apache Iceberg utilise Parquet par défaut pour stocker les données, tandis que ses métadonnées permettent des fonctionnalités avancées comme l'évolution du schéma sans rupture.
Comparaison avec d'autres formats
| Critère | Parquet | CSV | JSON | Avro |
|---|---|---|---|---|
| Orientation | Colonne | Ligne | Ligne | Ligne |
| Compression | Excellente | Faible | Moyenne | Bonne |
| Performances | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| Schéma | Requis | Optionnel | Optionnel | Requis |
| Cas d'usage | Analytique | Échange simple | Données semi-structurées | Streaming |
Légende : ⭐ (faible) à ⭐⭐⭐⭐⭐ (excellent).
Parquet excelle pour les charges de travail analytiques, tandis que des formats comme Avro sont mieux adaptés au streaming.
Cas d'usage pratiques
1. Optimisation des coûts de stockage
Grâce à sa compression efficace, Parquet réduit significativement l'espace disque nécessaire. Par exemple, un fichier CSV de 100 Go peut être réduit à 20 Go en Parquet.
2. Accélération des requêtes
Dans un environnement Spark, les requêtes sur des données en Parquet sont jusqu'à 10x plus rapides que sur des CSV, car seules les colonnes pertinentes sont lues.
3. Intégration avec Iceberg pour la gouvernance
En combinant Parquet avec Apache Iceberg, vous bénéficiez :
- D'un historique complet des modifications (snapshots).
- De métadonnées détaillées gérées par Iceberg pour une gouvernance améliorée, incluant par exemple des statistiques précises au niveau de chaque fichier Parquet (comme les valeurs min/max par colonne) et des informations claires sur le partitionnement des données, permettant ainsi un suivi et un audit plus rigoureux.
- De transactions ACID pour des mises à jour sécurisées.
Avantages clés de Parquet
- Performance :
- Requêtes plus rapides grâce au stockage colonnaire.
- Compression élevée réduisant les coûts de stockage.
- Interopérabilité :
- Supporté par tous les outils majeurs (Spark, Flink, Presto, etc.).
- Format de choix pour les architectures lakehouse.
- Évolutivité :
- Adapté aussi bien aux petits (à partir de 10 Mo) qu'aux très grands volumes de données.
- Efficacité :
- Réduction des coûts de calcul et de stockage.
Conclusion : Pourquoi choisir Parquet ?
Apache Parquet est bien plus qu'un simple format de stockage : c'est la pierre angulaire des architectures modernes de données. Que vous utilisiez un data lake, un lakehouse, ou des outils comme Spark et Iceberg, Parquet offre un équilibre parfait entre performance, efficacité et flexibilité.
Recommandation
- Pour des besoins analytiques, Parquet est incontournable.
- Pour des fonctionnalités avancées (ACID, Time Travel), combinez-le avec Delta Lake, Hudi, ou Iceberg.
En adoptant Parquet, vous optimisez non seulement vos coûts, mais aussi la rapidité et la fiabilité de vos pipelines de données.