L'architecture Data Lake expliquée
Explication de l'infographie "How Data Lake Architecture Works" de ByteByteGo.

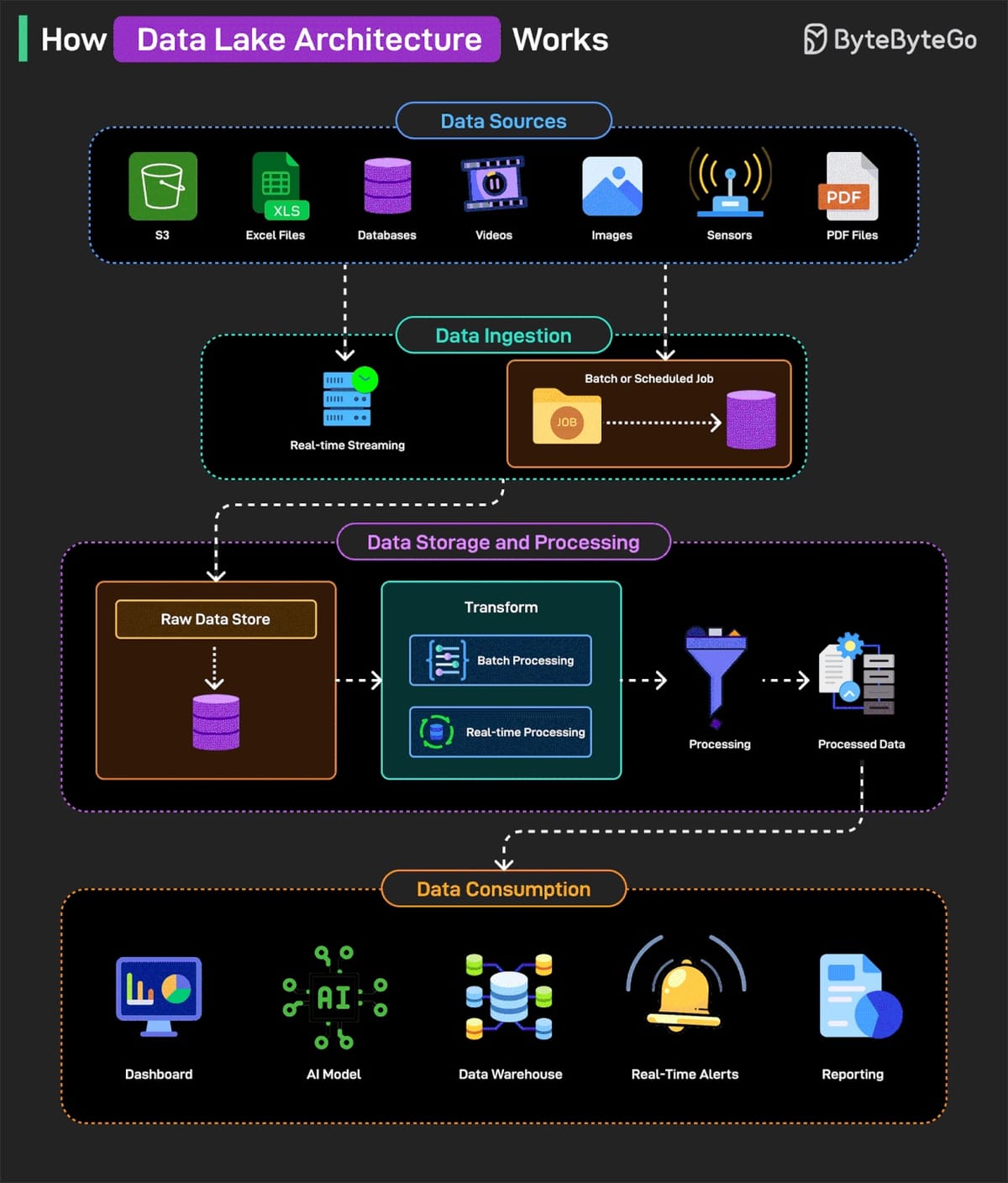
Les infographies de ByteByteGo passent régulièrement sur mon flux LinkedIn. J'ai notamment retenu celle-ci : How Data Lake Architecture Works.
1. Sources de données (Data Sources)
Il s'agit des sources initiales d'où sont collectées toutes les données brutes. Un Data Lake est conçu pour ingérer une grande variété de données, qu'elles soient structurées, semi-structurées ou non structurées.
- S3 (Amazon Simple Storage Service) : Un service de stockage d'objets dans le cloud, très utilisé pour stocker de grandes quantités de données brutes.
- Fichiers Excel : Données tabulaires classiques.
- Bases de données : Données structurées provenant de systèmes transactionnels (ex. : MySQL, PostgreSQL) ou non transactionnels (NoSQL).
- Vidéos, images, capteurs, fichiers PDF : Exemples de données non structurées ou semi-structurées qui peuvent être ingérées directement. Les données de capteurs peuvent être des séries temporelles.
2. Ingestion des données (Data Ingestion)
C'est le processus par lequel les données sont collectées et déplacées des sources vers le Data Lake. Il existe deux principales méthodes :
- Streaming en temps réel (Real-time Streaming) : Pour les données qui arrivent continuellement et doivent être traitées ou stockées immédiatement (ex. : données de capteurs, clics sur un site web).
- Traitement par lots (Batch or Scheduled Job) : Pour les données qui sont collectées et traitées à des intervalles réguliers (ex. : une fois par jour, une fois par heure).
3. Stockage et traitement des données (Data Storage and Processing)
C'est le cœur du Data Lake.
- Stockage des données brutes (Raw Data Store) : C'est la zone où toutes les données ingérées sont stockées dans leur format original, sans aucune modification. C'est le principe même d'un Data Lake : stocker tout, au cas où. Cela permet de revenir aux données originales si nécessaire pour de nouvelles analyses.
- Transformation (Transform) : C'est l'étape où les données brutes sont préparées pour l'analyse. Cela implique de nettoyer, de structurer, d'agréger ou d'enrichir les données.
- Traitement par lots (Batch Processing) : Pour les transformations lourdes et complexes qui peuvent être exécutées sur de grands volumes de données à intervalles réguliers.
- Traitement en temps réel (Real-time Processing) : Pour les transformations qui doivent être effectuées sur des flux de données en temps réel.
- Traitement (Processing) : Après la transformation, les données sont traitées pour être prêtes à l'emploi. Cela peut inclure des agrégations, des jointures, des filtrages, etc.
- Données traitées (Processed Data) : Ce sont les données qui ont été nettoyées, transformées et structurées, prêtes à être consommées par les utilisateurs ou les applications. Elles sont souvent stockées dans un format plus optimisé pour l'analyse, comme Parquet ou ORC.
4. Consommation des données (Data Consumption)
Une fois que les données sont traitées, elles peuvent être utilisées pour diverses applications et par différents utilisateurs.
- Tableau de bord (Dashboard) : Les données sont visualisées via des outils de Business Intelligence (BI) pour fournir des aperçus et des métriques (ex. : ventes, performance du site web).
- Modèle d'IA : Les données traitées peuvent être utilisées pour entraîner des modèles d'intelligence artificielle ou de machine learning pour des prédictions, des classifications, etc.
- Data Warehouse : Les données structurées et nettoyées peuvent être déplacées vers un Data Warehouse. Un Data Warehouse est une base de données optimisée pour le reporting et l'analyse, souvent avec un schéma prédéfini. Contrairement au Data Lake qui stocke tout, le Data Warehouse est plus sélectif et structuré.
- Alertes en temps réel : Les données traitées en temps réel peuvent déclencher des alertes immédiates en cas d'événements spécifiques (ex. : dépassement d'un seuil, détection d'anomalie).
- Rapports : Génération de rapports réguliers pour les décideurs ou pour des analyses approfondies.
En résumé, un Data Lake offre une flexibilité énorme pour stocker et traiter toutes sortes de données. Il permet de capturer les données brutes sans savoir à l'avance comment elles seront utilisées, et de les transformer au fur et à mesure des besoins pour diverses applications analytiques ou opérationnelles. C'est une architecture puissante pour gérer la complexité et le volume croissant des données modernes.

