Introduction à Data Mesh
Data Mesh : solution aux limites des data lakes ?

Selon une étude de Thoughtworks, plus de 50% des dirigeants sont insatisfaits de leur gestion des données. Malgré des investissements massifs dans les data lakes et les data warehouses, les entreprises peinent toujours à en tirer une réelle valeur métier. Les approches centralisées, conçues pour uniformiser la gestion des données, se heurtent à des problèmes d’échelle, de qualité et d’agilité.
C’est dans ce contexte qu’émerge le Data Mesh, une approche radicalement différente. Inspiré des principes des microservices et du Domain-Driven Design, le Data Mesh propose une décentralisation des responsabilités, où chaque domaine métier gère ses propres données comme des produits autonomes.
Mais le Data Mesh est-il vraiment une révolution, ou simplement une évolution naturelle des architectures data ? Dans cet article, nous explorons ses principes, ses avantages, ses défis, et les cas concrets où il fait la différence.
Le concept du Data Mesh
Data Lake vs Data Mesh : un outil vs un framework
Pour bien saisir l’apport du Data Mesh, il faut distinguer deux niveaux :
Le Data Lake : un outil de stockage centralisé
Le Data Lake est avant tout une solution technologique : un dépôt unique où sont stockées des données brutes ou traitées. Son rôle ?
- Centraliser les données dans un même espace (cloud ou on-premise).
- Standardiser leur accès via des outils comme Hadoop, Spark ou Delta Lake.
Mais cette approche purement technique révèle des limites organisationnelles :
- Gouvernance passive : Les données y sont déposées sans toujours être structurées ou documentées.
- Dépendance à l’équipe data : Les métiers attendent que les données soient préparées pour eux.
Le Data Mesh : un cadre organisationnel
Le Data Mesh n’est pas un outil, mais un framework de gestion des données qui redéfinit les responsabilités et les processus. Il repose sur :
- Une philosophie : Les données sont des produits gérés par les métiers, pas des artefacts techniques.
- Des principes structurants :
- Décentralisation : Chaque domaine (marketing, finance, etc.) est propriétaire de ses données.
- Autonomie : Les équipes publient des données prêtes à l’emploi (avec documentation, SLA).
- Infrastructure partagée : Une plateforme self-service évite la redondance des outils.
Complémentarité possible
Un Data Mesh peut s’appuyer sur des Data Lakes par domaine (ex. : un Lake pour la logistique, un autre pour le marketing). La différence clé ?
- Avec un Lake seul, l’accent est mis sur la technologie de stockage.
- Avec un Mesh, l’accent est mis sur l’organisation et la valeur métier.
Exemple concret :
- Approche Data Lake classique : Toutes les données de l’entreprise sont dans un seul lake ; l’équipe data les transforme à la demande.
- Approche Data Mesh : Chaque service a son propre "produit data" (stocké dans un lake ou autre) et le met à disposition via des APIs standardisées.
4 principes du Data Mesh
1. Domaines de données
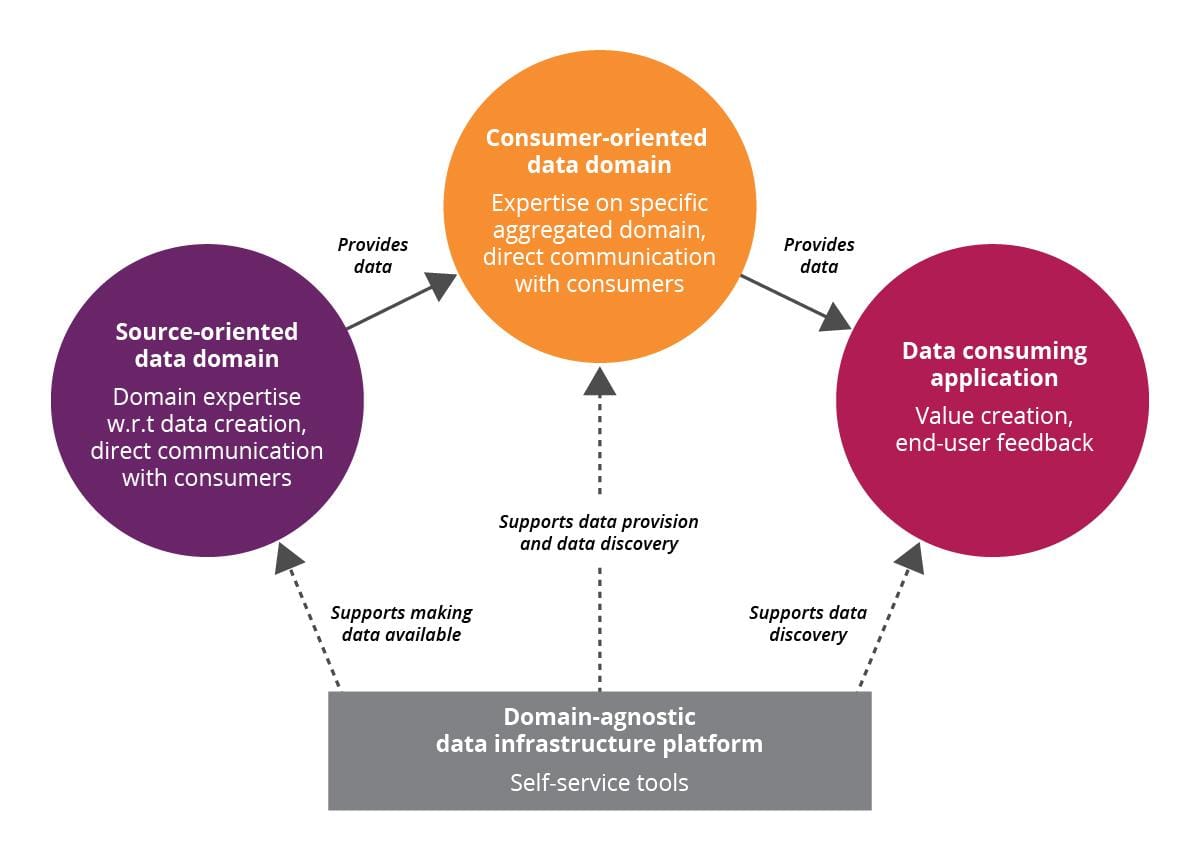
Au lieu d’avoir une équipe data centrale, chaque domaine métier est responsable de :
- Produire ses propres données analytiques.
- Garantir leur qualité et leur utilité.
- Les exposer sous forme de produits consommables.
2. Produits Data
Les données ne sont plus des fichiers bruts, mais des produits avec :
- Une documentation complète (schémas, dictionnaires de données).
- Des indicateurs de qualité (ex. : fraîcheur, complétude).
- Des interfaces standardisées (APIs, événements, fichiers structurés).
3. Plateforme Self-Service
Pour éviter que chaque équipe ne réinvente l’infrastructure, une plateforme commune fournit :
- Outils de stockage, transformation et orchestration.
- Gestion des métadonnées (catalogage, lignage).
- Supervision des SLA (ex. : temps de disponibilité).
4. Gouvernance des données
Au lieu d’un contrôle centralisé, des règles globales sont appliquées automatiquement :
- Politiques de confidentialité (Privacy by Design).
- Standards de qualité (ex. : validation des schémas).
- Mécanismes de découverte (métadonnées enrichies).
Exemples d’utilisation
ITV : Publicité contextuelle grâce au Data Mesh
- Problème : Les équipes marketing et contenu ne collaboraient pas, faute d’accès aux bonnes données.
- Solution : Un Data Mesh a permis de relier les métadonnées des émissions aux données publicitaires.
- Résultat : +30% d’efficacité sur les campagnes ciblées.
Roche Diagnostics : Données industrielles en temps réel
- Problème : Les données de production n’étaient disponibles que mensuellement, entraînant des stocks excédentaires.
- Solution : Les usines publient désormais leurs données en direct via des produits data autonomes.
- Résultat : Réduction des coûts de stockage et des ruptures d’approvisionnement.
3. Bosch : Optimisation énergétique grâce au Data Mesh
- Problème : Les données des piles à combustible (SOFC) étaient fragmentées, limitant l’analyse en temps réel.
- Solution : Une plateforme cloud-native intégrant IoT et digital twins pour un monitoring précis.
- Résultat :
- Réduction des coûts de fabrication via l’optimisation des paramètres de production.
- Surveillance en temps réel de l’état des unités déployées.
✅ Avantages du Data Mesh
Accès démocratisé
Données en libre-service pour tous, réduisant les silos et accélérant les décisions.
Coûts optimisés
Infrastructure cloud élastique (pay-as-you-go) et traitement en temps réel.
Dette technique réduite
Maintenance simplifiée grâce à la décentralisation et aux APIs standardisées.
Données interopérables
Schémas et métadonnées harmonisés entre domaines pour une intégration fluide.
Conformité robuste
Contrôles d’accès granulaires et traçabilité native pour les audits.
Quand (et quand ne pas) adopter le Data Mesh ?
✅ Idéal pour :
- Grandes organisations avec plusieurs domaines complexes.
- Entreprises cloud-native ayant une culture DevOps.
- Secteurs régulés (finance, santé) où la gouvernance est critique.
❌ À éviter si :
- Structure petite avec des besoins data simples.
- Pas de culture produit ou de collaboration transverse.
- Équipes data déjà sous-dimensionnées.
Conclusion
Le Data Mesh n’est pas une solution magique, mais une réponse pragmatique aux échecs des modèles centralisés. En redistribuant la complexité au plus près des métiers, il permet une meilleure qualité, une plus grande agilité et des coûts maîtrisés.
Cependant, son succès dépend moins de la technologie que de l’évolution des mentalités : sans une vraie culture produit et une gouvernance fédérée, le Data Mesh risque de créer plus de problèmes qu’il n’en résout.
Sources
- Introduction to Data Mesh - Zhamak Dehghani | YouTube/@Thoughtworks
- Data mesh | Thoughtworks
- Beyond Technology: Creating Business Value with Data Mesh | Thoughtworks
- Bosch Building a lean, evolutionary data platform and pipelines for efficient green energy | Thoughtworks
- Qu'est-ce que le data mesh ? | IBM
- Data Mesh Principles and Logical Architecture
- Data Mesh / Data Meshing : Explication et définition du concept | DataBird
- 10 recommendations for a successful enterprise data mesh implementation | Thoughtworks

