DataOps : La clé pour industrialiser et valoriser vos données
DataOps optimise la gestion des données via automatisation, tests et gouvernance. Idéal pour les entreprises cherchant rapidité, qualité et conformité. Essentiel pour industrialiser les flux data.

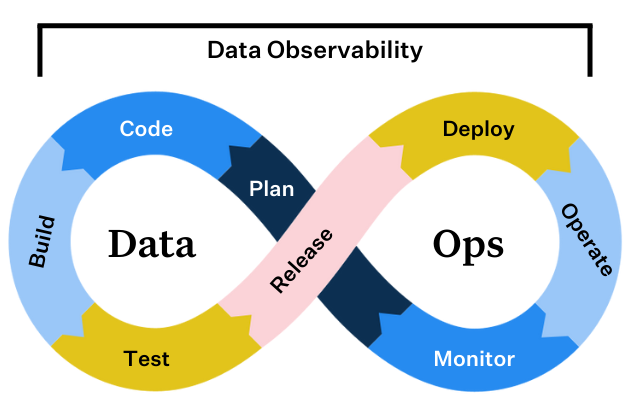
Dans le monde actuel axé sur les données, les entreprises cherchent constamment des moyens d'optimiser leurs opérations de données. Découvrez DataOps, une approche méthodologique conçue pour améliorer la qualité et réduire le temps de cycle de l'analyse des données. S'inspirant des principes DevOps, DataOps vise à rationaliser la communication, le déploiement, l'intégration et l'automatisation entre les producteurs et les consommateurs de données. Cet article de blog explorera les facettes de DataOps, en s'appuyant sur les connaissances d'experts du domaine.
Qu'est-ce que DataOps et pourquoi est-ce nécessaire ?
DataOps consiste à rendre les tâches répétitives liées aux données plus intelligentes et standardisées. Pensez à l'ajout de nouvelles sources de données, à la transformation des données et à leur mise à disposition. DataOps cherche à systématiser ces processus, en particulier dans les organisations décentralisées dotées de plusieurs équipes de données.
Il est crucial de faire la distinction entre Data Engineering et DataOps. Une équipe DataOps construit le cadre, les processus et la méthodologie permettant aux données de circuler efficacement d'un point A à un point B. Cela répond ainsi aux cas d'utilisation métier. Les Data Engineers, quant à eux, opèrent dans ce cadre pour mettre en œuvre des cas d'utilisation spécifiques, charger des données et garantir que les analystes et les scientifiques des données disposent des données dont ils ont besoin. DataOps exige souvent des compétences supplémentaires en matière d'infrastructure, de DevOps et d'intégration et de livraison continues (CI/CD).
La nécessité de DataOps se fait sentir lorsque les entreprises cherchent à :
- Augmenter efficacement l'échelle de leurs opérations de données.
- Améliorer la vitesse et la qualité de la livraison des projets de données.
- Passer de manière transparente des environnements de développement / test à la production.
Qui bénéficie de DataOps ?
L'approche DataOps, bien que flexible, apporte une valeur particulièrement tangible à divers types d'organisations confrontées à des défis spécifiques liés à leurs données :
Grandes entreprises
Souvent dotées de multiples équipes de données, ces organisations luttent fréquemment contre les silos de données, l'hétérogénéité des outils et des processus, et la difficulté à maintenir une gouvernance cohérente à grande échelle. DataOps leur offre un cadre pour standardiser les pratiques, automatiser les flux de travail complexes, améliorer la collaboration entre les équipes et garantir la qualité et la conformité des données sur de vastes périmètres. Cela se traduit par une réduction des erreurs, une accélération de la mise à disposition des données fiables et une meilleure agilité pour répondre aux besoins métiers globaux.
Scale-ups
Ces entreprises connaissent une augmentation rapide du volume de données, de la complexité des cas d'usage et de la taille de leurs équipes. Sans une approche structurée, elles risquent de développer une dette technique importante et de voir leurs processus de données devenir des goulots d'étranglement. DataOps permet aux scale-ups d'industrialiser leurs opérations de données dès le départ ou en cours de croissance, assurant la scalabilité des pipelines, la qualité des données pour des décisions rapides et la capacité à innover sans être ralenties par des processus manuels et fragiles. Même avec des équipes DataOps initialement réduites, l'impact sur l'efficacité et la capacité à soutenir la croissance est considérable.
Petites et Moyennes Entreprises (PME) et Start-ups
Pour ces structures, DataOps peut sembler un investissement initial lourd, mais son adoption progressive offre des avantages décisifs. En intégrant dès le départ des principes clés comme l’automatisation des tests, le monitoring des pipelines et des outils low-code (ex : Airflow, Prefect), ces structures peuvent éviter une dette technique coûteuse tout en garantissant la qualité des données. Un Data Engineer polyvalent, couplé à des plateformes cloud modernes (BigQuery, Snowflake, etc.), peut implémenter des processus légers mais robustes. Cela permet d’itérer rapidement sur les produits data sans sacrifier la fiabilité – un atout critique pour les jeunes entreprises en croissance.
Mettre en œuvre une approche DataOps : Les piliers clés
Selon Gartner et les experts du secteur, la mise en œuvre de DataOps s'articule autour de plusieurs piliers fondamentaux.
- Orchestration : Il s'agit de gérer et d'automatiser les pipelines de données, qui sont des séquences de traitements de données. Cela garantit que les tâches sont déclenchées par des événements spécifiques ou exécutées à des moments précis.
- Observabilité : Le suivi des pipelines de données est essentiel pour s'assurer qu'ils fonctionnent correctement. Cela inclut de savoir que les données sont fiables et de bonne qualité pour les équipes métier et de comprendre les coûts associés aux projets de données.
- Gestion des environnements : Fournir aux praticiens des données (ingénieurs, scientifiques) les outils nécessaires à chaque étape du projet est crucial. Cela peut impliquer la fourniture automatisée d'environnements de développement (par exemple, DBT, Snowflake) avec des tests, des modules de déploiement et une orchestration préconfigurés.
- Déploiement automatisé (CI/CD) : Faciliter le passage du développement à la production sans intervention constante des équipes IT ou Ops est un avantage clé. Cela implique de standardiser les processus de déploiement et les tests pour la qualité du code et des données.
- Tests : La mise en œuvre de tests automatisés et de cycles de validation tout au long du processus de développement est fondamentale pour garantir la qualité et l'intégrité des données.
Matthieu Rousseau, fondateur de Modeo, ajoute une couche de gouvernance comme un ensemble englobant de piliers :
- Gouvernance technique : Meilleures pratiques, modules et outils mis à disposition des équipes de données (par exemple, environnement de développement, processus de déploiement, documentation, FinOps).
- Gouvernance métier : Aligner les projets techniques sur les objectifs métier, prioriser les demandes, mettre en place une observabilité des données pour le métier et implémenter un catalogue de données.
- Gouvernance de la sécurité : Définir et appliquer des règles d'accès aux données (par exemple, accès basé sur les rôles dans Snowflake, masquage des données).
- Gouvernance légale (par exemple, RGPD) : Définir les actions de conformité, y compris la gestion du cycle de vie des données (purge automatisée des données) et la modélisation des données pour protéger les données personnelles.
- Gouvernance RSE (responsabilité sociétale des entreprises) : Surveiller et optimiser l'impact carbone des activités liées aux données.
Démarrer avec DataOps : premières étapes
Lancer une initiative DataOps peut sembler intimidant, mais voici quelques étapes initiales :
- Définir clairement les responsabilités entre l'équipe DataOps et les autres équipes de données. Par exemple, l'équipe DataOps pourrait fournir le système d'orchestration, tandis que les autres équipes de données gèrent l'ingestion.
- Établir une base technique solide : Des environnements standardisés sont essentiels. Imaginez un projet de données qui peut être lancé en quelques clics, avec des modèles DBT, des processus de documentation et une CI/CD prêts à l'emploi.
- Prioriser en fonction du contexte : Toutes les entreprises n'ont pas les mêmes points faibles. Identifiez si les plus grands défis concernent les tests, l'orchestration ou un autre domaine, et concentrez-vous sur ces aspects en premier.
L'évolution du rôle du Data Engineer
L'adoption de DataOps introduit une nouvelle dimension dans le métier de Data Engineer : la maîtrise des outils d'automatisation et de configuration. Si certaines tâches se simplifient techniquement (comme l'ajout de sources via des fichiers de configuration YAML), le rôle gagne en importance stratégique pour concevoir et maintenir ces systèmes automatisés.
Ce changement libère les Data Engineers pour qu'ils se consacrent à :
- Des défis techniques plus complexes, ouvrant potentiellement la voie à des rôles DataOps.
- Des tâches plus proches du métier, telles que l'Analytics Engineering.
- Des projets d'IA Générative (GenAI), qui nécessitent souvent de solides compétences en ingénierie des données pour la mise en production et le traitement des données.
Dans un contexte DataOps bien établi, un Data Engineer peut devenir plus évolutif et soutenir un plus grand nombre d'analystes de données. Toutefois, cette augmentation de la capacité est conditionnée par plusieurs facteurs, notamment la standardisation des pipelines de données, l'efficacité des outils d'automatisation et la clarté des rôles et responsabilités au sein de l'équipe Data.
Avantages d'une approche DataOps
L'adoption de DataOps offre une multitude d'avantages :
- Vélocité accrue : Impact significatif sur la rapidité des équipes de développement, réduisant le délai de valorisation des projets de données.
- Amélioration de la qualité des données : Les pipelines standardisés et une meilleure observabilité conduisent à une meilleure qualité des données.
- Conformité améliorée (par exemple, RGPD).
- Meilleure collaboration : Une équipe DataOps centralisée peut favoriser une meilleure collaboration entre les différents domaines.
- Efficacité et fiabilité accrues des projets de données.
Défis de la mise en œuvre de DataOps
Bien que bénéfique, la mise en place de DataOps présente certains défis :
- Cartographie complexe : Comprendre et cartographier les projets Data, les produits et les ressources existants peut s'avérer complexe.
- Gestion du changement : Surmonter la résistance aux nouvelles méthodes de travail nécessite une sensibilisation et une formation adéquates.
- Éviter la rigidité : Il est crucial de s'assurer que les processus standardisés ne deviennent pas trop restrictifs et peuvent s'adapter aux cas d'utilisation futurs.
- Rôle de l'équipe DataOps : L'équipe DataOps doit être perçue comme un bâtisseur de solutions standardisées à long terme, et non comme un simple centre de services pour résoudre les problèmes immédiats.
Outils DataOps et marché
Le marché des solutions DataOps offre un éventail d'approches et d'outils pour répondre aux besoins variés des entreprises :
Développement interne et solutions open-source
Les entreprises peuvent choisir de construire leurs propres plateformes DataOps en s'appuyant sur des outils open-source. Des solutions existent pour différentes fonctionnalités clés comme l'orchestration de workflows (Apache Airflow étant un exemple populaire), l'intégration de données, la gestion de la qualité ou l'observabilité. Cette approche permet une personnalisation maximale et un contrôle total sur l'environnement. Cependant, elle peut impliquer un coût global plus élevé, notamment en termes de temps de développement initial, de compétences spécifiques requises et de maintenance continue.
Plateformes DataOps commerciales et solutions clés en main
De nombreux éditeurs (dont DataKitchen) proposent des plateformes DataOps intégrées. Ces solutions visent à fournir un ensemble cohérent de fonctionnalités couvrant plusieurs aspects du cycle de vie des données, tels que l'automatisation des pipelines, la gestion des environnements, le monitoring, la qualité des données et la gouvernance. L'avantage principal réside dans une mise en œuvre potentiellement plus rapide et un support centralisé. En contrepartie, elles peuvent offrir moins de flexibilité pour des besoins très spécifiques et introduire une dépendance vis-à-vis du fournisseur.
Évolution du marché
Le marché DataOps est dynamique et en constante évolution. La tendance est à une intégration plus poussée des différentes briques fonctionnelles au sein de plateformes unifiées. On observe également une incorporation croissante de l'intelligence artificielle pour automatiser davantage les processus et améliorer l'observabilité des systèmes de données. Il est important de noter que des outils spécialisés dans un domaine, comme Apache Airflow pour l'orchestration, constituent souvent des composants essentiels d'une stratégie DataOps globale plutôt qu'une solution DataOps complète en soi.
Conclusion
DataOps est bien plus qu'un simple mot à la mode. C'est une approche stratégique essentielle pour les organisations modernes axées sur les données qui cherchent à industrialiser leurs processus de données et à en extraire une valeur maximale. En se concentrant sur l'automatisation, la collaboration et l'amélioration continue, DataOps permet aux équipes de fournir des informations de haute qualité plus rapidement et plus efficacement.
Sources
Tout comprendre sur le DataOps 💪 | YouTube/DataGen
Saagie : C’est quoi le DataOps ?! 🤔 | YouTube/DataGen
Definition of DataOps | Gartner
DataOps Explained: How To Not Screw It Up | Monte Carlo

