Quelle est la différence entre un Data Lake et un Data Warehouse ?
Un data lake stocke des données brutes sans schéma défini, idéal pour le stockage flexible. Le data warehouse structure et nettoie les données pour l'analyse métier. Découvrez comment choisir entre ces deux solutions pour vos besoins en gestion de données.

Introduction
Avec l'écosystème des données en pleine expansion, de nouveaux termes apparaissent chaque semaine. Parmi les plus populaires, on trouve "data lakes" et "data warehouses" (rappel : l'article original a été publié en 2022). Si vous :
- Essayez de comprendre les différences entre un data lake et un data warehouse
- Vous sentez frustré par le marketing des vendeurs qui cherchent à promouvoir leurs produits lake / warehouse ?
Alors cet article est fait pour vous. À la fin de cette lecture, vous comprendrez ce que sont les data lakes et les data warehouses, et comment choisir les bons outils pour vos projets.
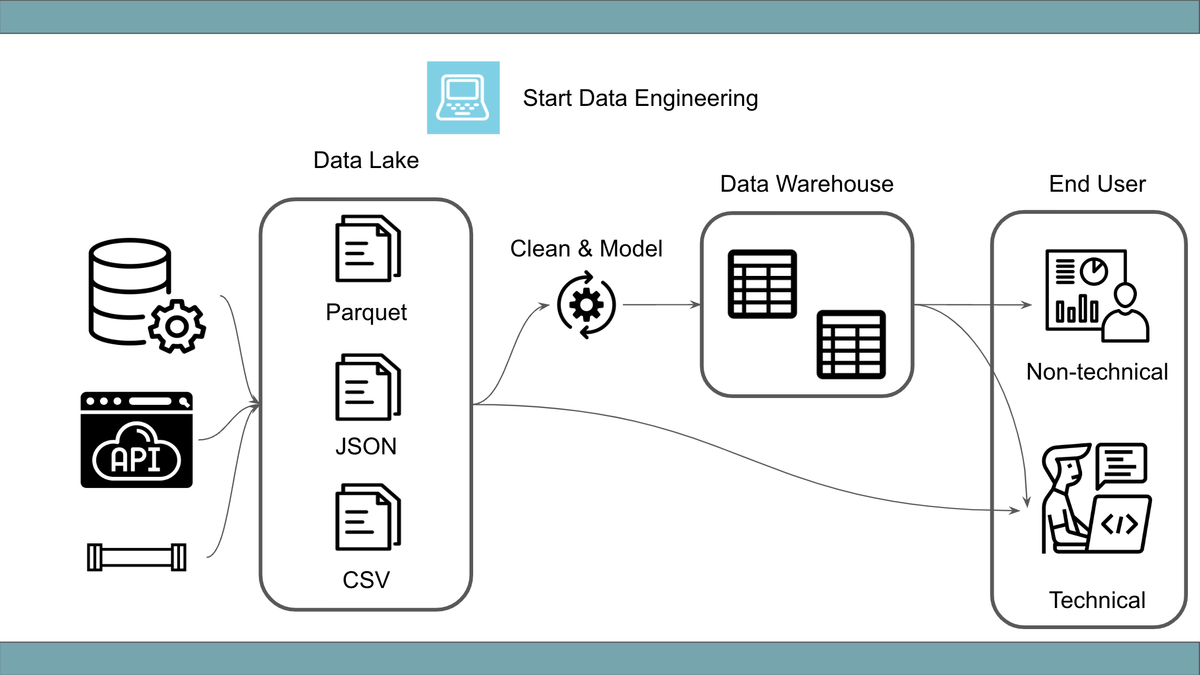
Data lakes et data warehouses
Data lake
Un data lake est un espace de stockage où les données brutes sont déversées et utilisées comme source pour votre data warehouse.
Comparé à un data warehouse, un data lake est rapide à mettre en place car il ne nécessite pas de nettoyage ni de modélisation des données.
Lecture recommandée : Qu'est-ce qu'une zone de staging ? (en)
Data warehouse
Le data warehousing est le processus qui consiste à comprendre les données, analyser les habitudes des utilisateurs finaux, organiser, nettoyer, modéliser et tester la qualité des données.
Le résultat du data warehousing est une base de données prête à l'emploi (le data warehouse). Les données d'un warehouse servent à calculer les KPI métiers critiques.
En raison du travail de curation et de nettoyage requis, sa mise en place est généralement plus lente que celle d'un data lake.
Lecture recommandée : Qu'est-ce qu'un data warehouse ? (en)
Comment choisir ?
Passons en revue les critères pour choisir vos outils. Traditionnellement, les data lakes étaient associés aux services de stockage cloud et les data warehouses aux bases OLAP. Mais avec des systèmes comme Delta Lake, Snowflake et ClickHouse, ces limites s'estompent.
| Élément | Service de stockage cloud (ex. S3) | Base de données OLAP (ex. Snowflake) |
|---|---|---|
| Schéma | Peut stocker des données de tout schéma. Des systèmes comme Spark peuvent inférer le schéma lors de la lecture (schema-on-read) |
Le schéma des données doit être défini pour les charger dans une table (schema-on-write). Certaines bases OLAP autorisent des colonnes non structurées (ex. stockage de données non structurées dans une colonne). |
| Format | Prend en charge tous les formats populaires et personnalisés. | Supporte les formats populaires (Avro, Parquet, ORC, etc.). La plupart ont leur propre format interne. |
| Volume | Coûte moins cher qu'une base de données OLAP. Varie généralement de quelques octets à des pétaoctets et des exaoctets. | Plus chère que le stockage cloud. Les données peuvent également être stockées dans le cloud et le schéma peut être défini comme une table externe. |
| Ingestion | Ingestion batch ou streaming. | Ingestion batch ou streaming (ex. : connecteur Snowflake-Kafka). |
| Lecture | Lecture en batch ou streaming, avec déclenchement d'événements sur réception de données. | Lecture en batch ou streaming (ex. : streams Snowflake). Pas de trigger sur données entrantes en OLAP. |
| Traitement | Nécessite un service dédié pour le traitement (ex. : Spark/Presto/Python). | Les SGBD OLAP sont optimisés pour le traitement massif de données, mais inefficaces pour des formats comme l'audio/vidéo. |
| Utilisateur final | Utilisateurs techniques requis pour accéder aux données. | Accessible via SQL ou outils de visualisation (Metabase, Looker). |
| Batch vs streaming | Utilisé principalement comme dépôt intermédiaire dans les processus de traitement batch et streaming. | Plus adaptée au batch en raison de la latence. Les vues matérialisées offrent des données à jour avec des limites. |
| Gestion des données | Les structures de dossiers, chemins d'accès, métadonnées, permissions, tailles de fichiers individuels, etc. devront être gérés. | La plupart des bases de données OLAP intègrent des tables de métadonnées et un schéma de permissions structuré, ce qui facilite leur gestion. |
Pour choisir un outil pour votre pipeline de données, utilisez le tableau ci-dessus. Notez que chaque système a ses spécificités - consultez sa documentation sur ces points.
L'idée principale est de considérer data lake et warehouse comme des concepts plutôt que des outils.

