Big Data
Apache Parquet : Le format de stockage incontournable pour le Big Data
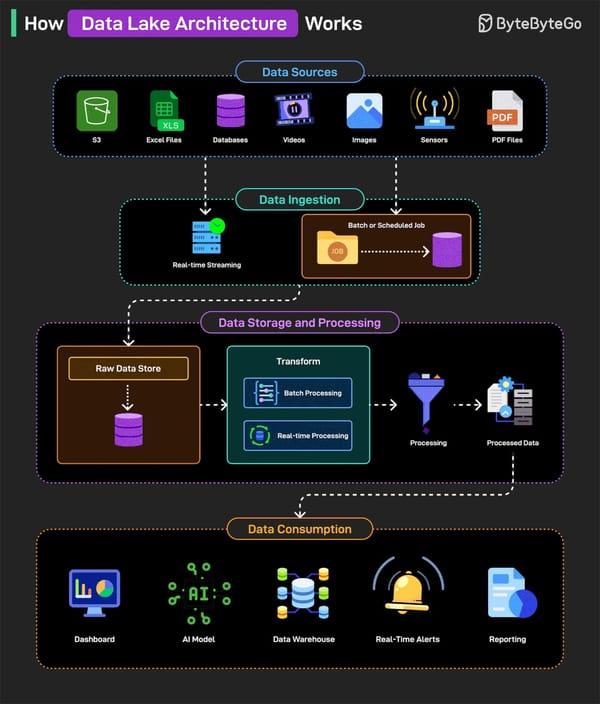
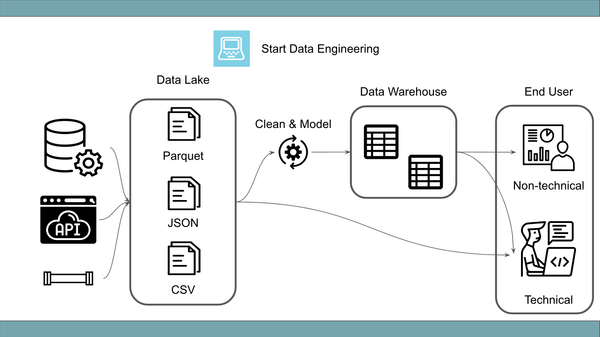
Apache Parquet est le format de stockage colonnaire incontournable pour le Big Data. Optimisé pour la performance et la compression, il accélère les requêtes et réduit les coûts. Intégré à Spark, Iceberg et les architectures lakehouse, Parquet offre interopérabilité et efficacité.